Laboratorio de Fuerza Bruta RDP con Splunk Enterprise
Introducción
En este laboratorio se simula un ataque de fuerza bruta contra el servicio RDP (Remote Desktop Protocol) en un entorno Windows 10. El propósito es demostrar el ciclo completo de detección y respuesta en un entorno SOC (Security Operations Center) empleando Splunk Enterprise como SIEM central y enfocándose en el flujo de trabajo de un analista de Nivel 1 (L1).
La dinámica permite observar cómo un atacante, utilizando herramientas automatizadas desde Kali Linux, genera múltiples intentos de inicio de sesión fallidos. Estos eventos son recolectados mediante Universal Forwarder, correlacionados en Splunk, y finalmente usados como disparador de alertas que inician un proceso de triaje.
Este escenario se ubica dentro de la fase de acceso Inicial de la Cyber Kill Chain y está alineado con la técnica T1110.001 – Brute Force (RDP) del marco MITRE ATT&CK.
Objetivos del laboratorio
- Simular un ataque de fuerza bruta contra RDP en un endpoint Windows utilizando Hydra desde Kali Linux.
- Recolectar, normalizar y analizar logs de seguridad (Event ID 4625 – Failed Logon) en Splunk.
- Correlacionar intentos fallidos mediante búsquedas en SPL para identificar patrones de ataque.
- Generar una alerta en Splunk que notifique vía correo electrónico.
Componentes Involucrados
| Rol | Detalles | Dirección IP |
|---|---|---|
| Máquina víctima | Windows 10 con servicio de Escritorio Remoto (RDP) habilitado. | 192.168.100.140 |
| Máquina atacante | Kali Linux, ejecutando Hydra para el ataque de fuerza bruta. | 192.168.100.110 |
| Recolector SIEM | Windows Server 2022 con Splunk Enterprise instalado. | 192.168.100.128 |
Ejecución del Ataque
El ataque se llevó a cabo desde la máquina Kali Linux utilizando la herramienta Hydra para realizar un ataque de fuerza bruta contra el servicio RDP del endpoint Windows.
En este escenario, se probó varios nombres de usuario combinados con un diccionario de contraseñas, con el objetivo de forzar accesos remotos no autorizados.
Recursos utilizados:
- Diccionario de contraseñas:
rockyou.txt - Lista de usuarios comunes:
top-usernames-shortlist.txtde SecLists
Este procedimiento generó múltiples eventos de autenticación fallida (Event ID 4625) en el endpoint Windows, los cuales fueron enviados a Splunk para su posterior detección y correlación.
Comando utilizado en Hydra
sudo hydra -V -f -u -L /usr/share/seclists/Usernames/top-usernames-shortlist.txt -P /usr/share/wordlists/rockyou.txt rdp://192.168.100.140
- -V Muestra cada intento de autenticación (verbose).
- -f Detiene el ataque si encuentra la primera combinación válida de usuario y contraseña.
- -u Intenta todas las contraseñas para cada usuario antes de cambiar a la siguiente cuenta de usuario.
- -L Archivo con lista de posibles usuarios.
- -P Archivo con diccionario de contraseñas.
rdp:// : Especifica el servicio RDP y la dirección IP de la máquina víctima
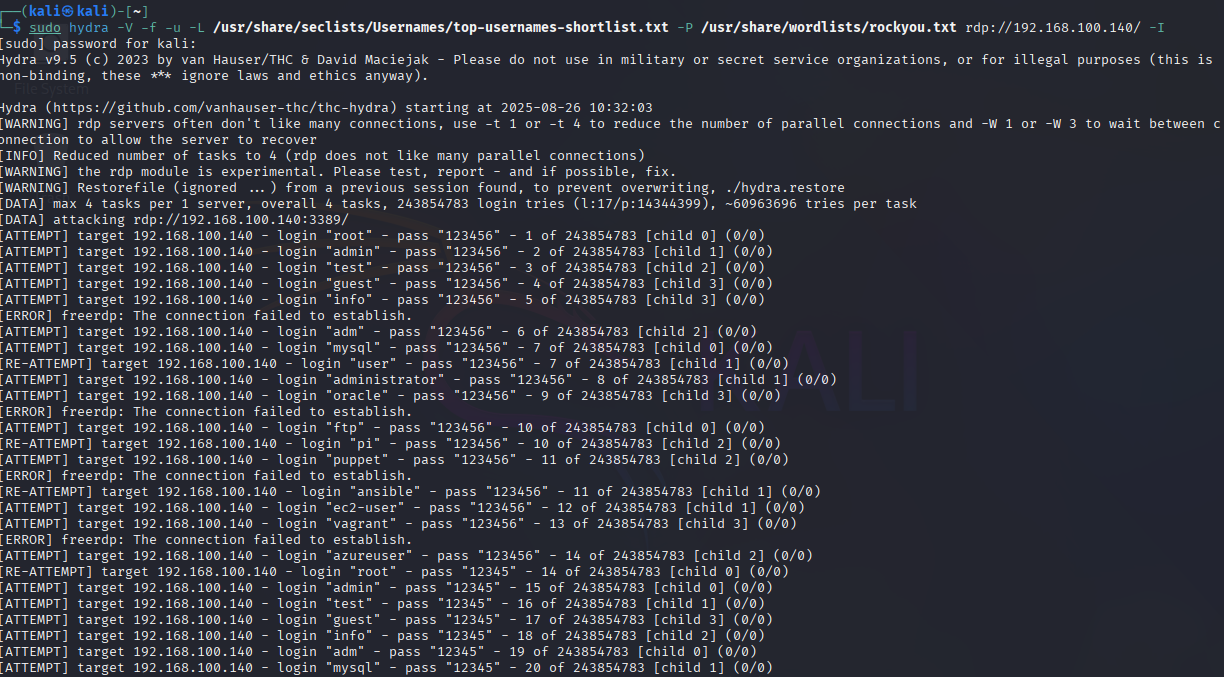
Este ataque genera múltiples eventos de inicio de sesión fallido (4625) en los registros de seguridad de Windows, los cuales son enviados a Splunk para su análisis y detección.
Eventos recolectados en Splunk
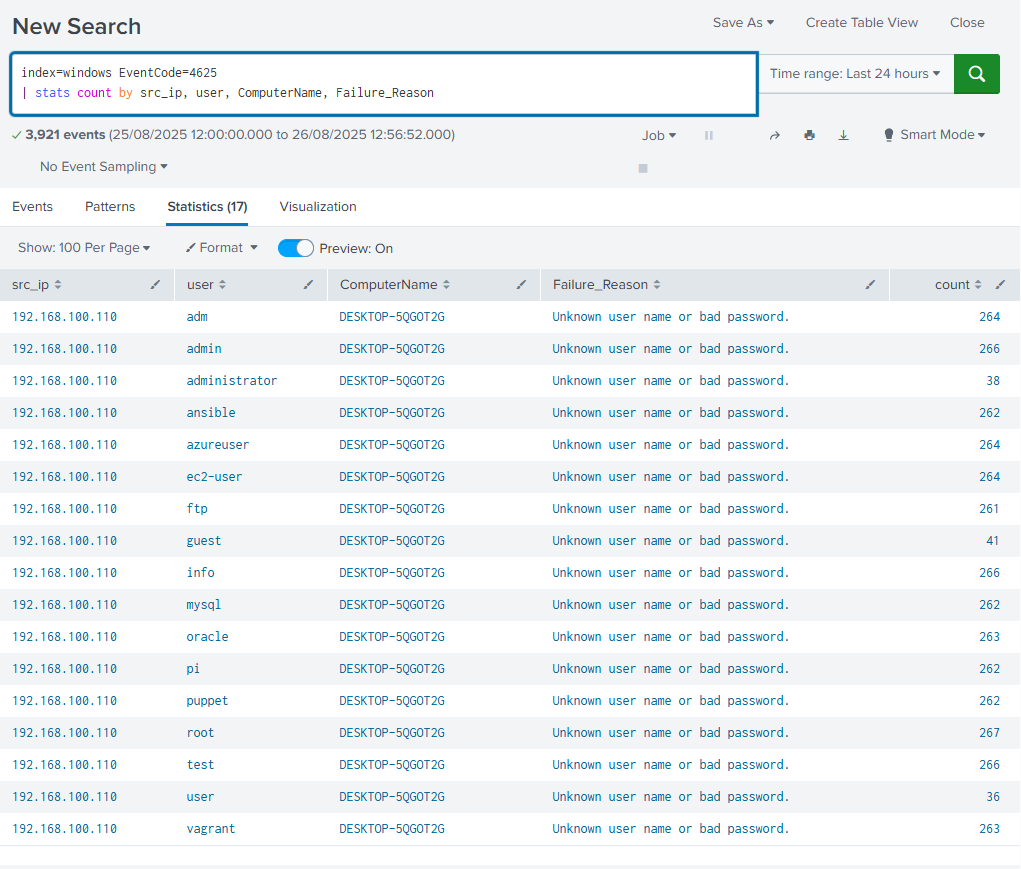
En la vista de Events se observa un registro con ID 4625 - An account failed to log on, generado en la máquina víctima.
Este evento evidencia un intento de inicio de sesión fallido desde la máquina atacante(en la correlación posterior también aparecen otros usuarios comunes (admin, root, test, oracle, etc.), lo que refuerza el patrón típico de un ataque de fuerza bruta.) :
- Event Code: 4625
- Computer Name: DESKTOP-5QGOT2G (corresponde a la máquina víctima Windows 10 con IP 192.168.100.140)
- Account Name: puppet
- Failure Reason: Unknown user name or bad password
- Workstation Name: kali
- Source Network Address: 192.168.100.110

Estos campos son los que permiten a Splunk identificar tanto el origen del ataque como el usuario objetivo.
Correlación con SPL
Una vez recolectados los eventos, se utilizó la siguiente búsqueda para obtener una visión general de los intentos fallidos:
index=windows EventCode=4625
| stats count by src_ip, user, ComputerName, Failure_Reason
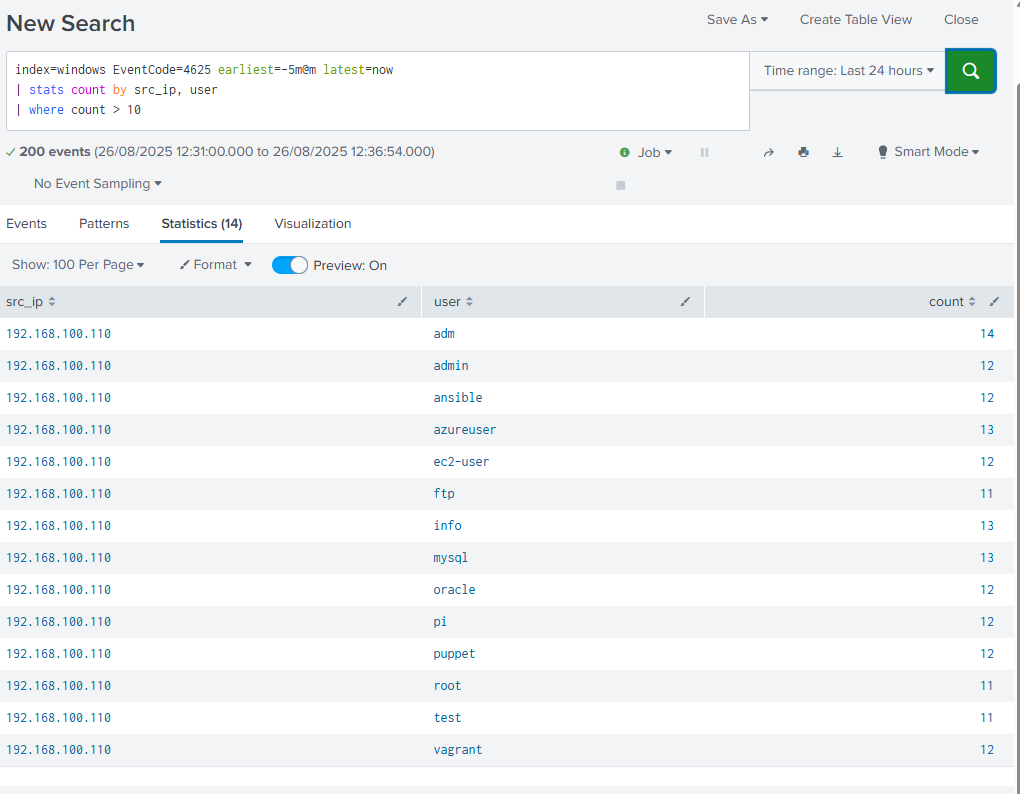
Posteriormente, la búsqueda se refinó para aplicar una ventana de 5 minutos y establecer un umbral de más de 10 intentos por combinación de IP y usuario. Esta versión final se utilizó como base para configurar la alerta de fuerza bruta en Splunk:
index=windows EventCode=4625 earliest=-5m@m latest=now
| stats count by src_ip, user
| where count > 10
Con esta búsqueda, Splunk es capaz de detectar de forma automática un patrón de ataque en tiempo casi real
Explicación de la consulta
- index=windows EventCode=4625 : filtra únicamente los eventos de seguridad con ID 4625 (Logon Failed) en el índice windows.
- earliest=-5m@m latest=now : limita la búsqueda a los últimos 5 minutos, creando una ventana de tiempo de correlación.
- stats count by src_ip, user : agrupa los resultados por IP de origen y usuario atacado, contando la cantidad de intentos fallidos.
- where count > 10 : aplica un umbral de más de 10 intentos fallidos en 5 minutos, criterio utilizado para identificar actividad de fuerza bruta.
Resultado obtenido
La ejecución de la consulta muestra que una misma IP atacante (192.168.100.110) realizó múltiples intentos de autenticación fallida contra diferentes cuentas de usuario (admin, root, test, oracle, etc.), superando el umbral establecido. Este patrón corresponde al comportamiento típico de un ataque de fuerza bruta con diccionario.
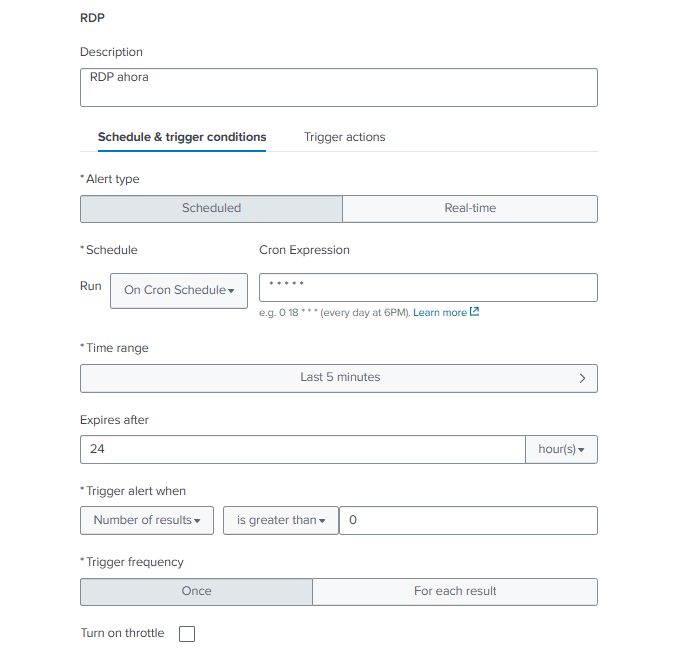
Configuración de la Alerta en Splunk
A partir de la búsqueda de correlación definida anteriormente, se creó una alerta en Splunk con el fin de automatizar la detección de intentos de fuerza bruta.
El criterio configurado fue identificar más de 10 intentos de autenticación fallidos en una ventana de 5 minutos desde la misma dirección IP.
Si la condición se cumple, se genera automáticamente un correo electrónico con los detalles de la detección.
Programación y condiciones de disparo
La alerta se programó con un intervalo de ejecución de 5 minutos.
Dentro de este período, si la consulta devuelve más de 0 resultados (es decir, si existe al menos una IP que supere el umbral de intentos fallidos), la alerta se activa y queda registrada.
En la siguiente captura se observa la sección de configuración relacionada con la frecuencia, rango de tiempo y condición de disparo:
Acciones configuradas
Como acción principal, se definió el envío automático de un correo electrónico con prioridad alta.
El mensaje generado incluye un resumen de la alerta y los campos relevantes (src_ip, user, count) que permiten identificar rápidamente la fuente del ataque.
La siguiente captura muestra la sección de configuración de acciones, donde se especifica el destinatario, asunto y contenido del correo:
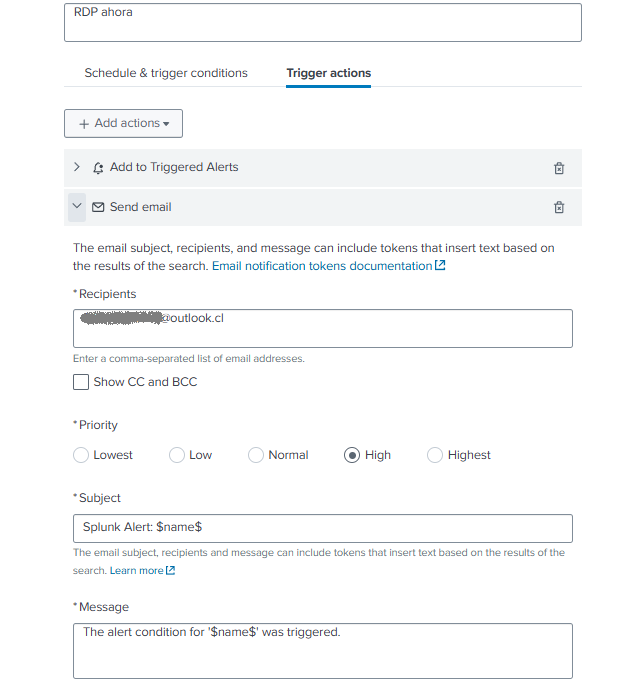
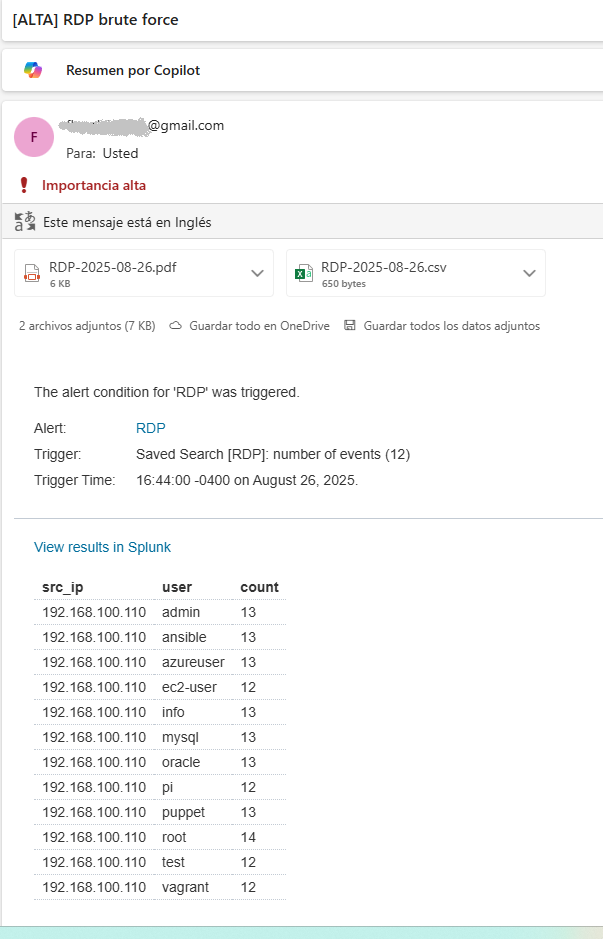
Notificación por Correo
Cuando la condición de la alerta se cumple, Splunk envía automáticamente un correo previamente definido en la configuracion de la alerta.
Este correo contiene:
- IP de origen del ataque (
src_ip) - Usuario objetivo (
user) - Cantidad de intentos fallidos (
count) - Enlace directo a Splunk para continuar la investigación
Triaje y Análisis Inicial (Flujo SOC L1)
Una vez que la alerta se activa, un analista de Nivel 1 (L1) iniciaría el proceso de triaje. Aunque este laboratorio no utiliza un sistema de ticketing, los pasos lógicos serían los siguientes:
- Recepción de la alerta: El analista L1 recibe la notificación por correo electrónico de Splunk.
- Creación de ticket: Se crea un nuevo ticket de incidente en la plataforma de ticketing del SOC, con la prioridad asignada y el título "Brute Force Attack - RDP".
- Análisis preliminar: El analista utiliza el enlace directo de la alerta para investigar en Splunk.
- Verifica los datos del incidente (IP de origen, número de intentos, nombres de usuario) para confirmar que se trata de un ataque de fuerza bruta real y no de un falso positivo (ej. un usuario olvidó la contraseña repetidamente).
- Confirma que la IP de origen no es una de las IPs corporativas o conocidas.
- Documentación: Se añaden al ticket los detalles clave del análisis: la consulta SPL, los eventos de log (EventCode=4625) y el resultado que muestra la IP y los usuarios afectados.
- Escalamiento: Dada la naturaleza del ataque, el analista L1 documenta los hallazgos en el ticket y escala el incidente a un nivel superior (L2) para la contención y respuesta, lo que podría incluir el bloqueo de la IP a nivel de firewall.
Conclusión del Hito
Con la creación de la alerta y la notificación por correo, queda implementada la fase de detección automatizada del ataque y el proceso de triaje inicial (L1). Este laboratorio demuestra la capacidad de monitorear eventos de seguridad, correlacionar datos para detectar amenazas y generar alertas que permiten a un analista iniciar una investigación de forma rápida y eficiente. Aunque el siguiente paso natural en un entorno de producción sería la respuesta automática o la contención, este laboratorio se centra en la primera fase del ciclo de vida de un incidente.